Une introduction claire à Apache Spark en français
Introduction
Il s’agit d’un projet de la fondation Apache issu de recherches à Berkeley. Ce projet fait maintenant partie des projets prioritaires de la fondation Apache avec des centaines de développeurs dans la plupart des gros acteurs du secteur big data.Apache Spark est un framework open source de traitement de données. Il est né d’une constatation simple : la technologie MapReduce est très intéressante mais dès que des requêtes complexes (itérées) sont nécessaires et que plus de temps réel entre en jeu, elle atteint ses limites. D’où l’idée de créer un nouveau framework utilisant la parallélisation massive avec une technologie in memory.
Avant d’aller plus loin voici deux petites définitions :
parallélisation massive : il s’agit de distribuer les calculs dans un grand nombre de processeurs ou de machines suivant la taille de votre infrastructure
in memory : il s’agit tout simplement de charger les données en mémoire c’est-à-dire dans la RAM des machines
Le fait de travailler sur une technologie in memory vient de deux constats :
Constat 1: la plupart des jeux de données de Big data font quelques Gigas et une utilisation de la mémoire RAM devient alors possible,
Constat 2: le coût de la mémoire (RAM) a très fortement baissé et on peut facilement obtenir des grandes quantités de mémoire
Grâce à ses principes, Spark permet de diviser par 100 les temps de calcul par rapport à l’utilisation de Mapreduce sur du Hadoop. De plus, il permet d’appliquer des algorithmes impossibles à mettre en oeuvre jusqu’ici avec les opérations de map et de reduce.
Dans quel cas utiliser Spark ?
Une chose est sûre, Spark n’est pas adapté à tous les contextes big data. De plus, combiner des clusters Hadoop pour le stockage et du Spark pour les traitements est aussi plus onéreux sachant qu’en plus de l’espace de stockage, il faut beaucoup de RAM supplémentaire.Néanmoins deux cas se distinguent pour lesquels le passage à Spark aura tout son sens :
a) vous avez des besoins d’analyses en temps réel. C’est là que Spark excelle.
b) Vous avez des besoins en terme d’analytics importants. Les composantes de Spark permettent de gérer de nombreux algorithmes puissants (grâce à MLlib).
On peut voir des applications avec Spark dans des cas de requêtes en temps réelles avec des temps de retour en seconde, des cas de traitement de flux notamment dans la détection de fraudes.
On peut aussi l’utiliser pour les données issues de multiples capteurs et leur analyse en temps réel dans le cadre de l’Internet des Objet.
L’environnement Spark se combine naturellement avec un autre projet important de la fondation Apache : Apache Mahout.
Apache Mahout est un projet de la fondation Apache visant à créer des implémentations d'algorithmes d'apprentissage automatique distribués. D'abord développé au-dessus de la plate-forme Hadoop1,2, Mahout a ensuite utilisé Apache Spark. Mahout est encore en cours de développement ; le nombre d'algorithmes implémentés a rapidement augmenté3, mais certains manquent encore.
Même si les algorithmes principaux proposés par Mahout pour faire du partitionnement de données et de la classification automatique sont implémentés avec Apache Hadoop en utilisant le paradigme MapReduce, les contributions ne sont pas restreintes à une base Hadoop, mais peuvent aussi être non distribuées ou utiliser un cluster ne tournant pas sur Hadoop. Cela permet l'intégration de projets externes dans Mahout.
https://fr.wikipedia.org/wiki/Apache_Mahout
Où se situe Spark dans l’écosystème big data ?
Spark est un framework permettant de traiter de manière complexe des données de types variés. Il se situe donc plutôt au niveau des étapes Map et Reduce qu’au niveau de l’infrastructure en elle-même. Spark se combine très bien avec des clusters Hadoop (en HDFS) et permet d’appliquer des algorithmes complexes sur des données issues de ces clusters. En effet, il permet de faire la même chose que MapReduce mais aussi de travailler sur du streaming, faire des requêtes interactives et appliquer des algorithmes d’apprentissage (machine learning).
Les capacités de cette technologie sont très importantes, on peut utiliser des clusters avec des milliers de nœuds et traiter des petabytes de données. Si votre jeu de données est trop grand pour être traité in memory, Spark va automatiquement utiliser uniquement les parties nécessaires pour pouvoir traiter ce jeu.
La notion centrale quand vous faites du Spark est le RDD, ou Resilient Distributed Dataset.
En décortiquant ce nom on peut un peu mieux le comprendre, on part de la fin :
Dataset : Il s’agit d’un jeu de données qui se parcourt comme une collection.
Distributed : Cette structure est distribuée afin d’être découpée pour être traitée dans les différents nœuds.
Resilient : Il est résilient, car il pourra être relu en cas de problème.
Le RDD est simple à créer et peut être obtenu à partir de multiples sources :
- Une collection (List, Set), transformée en RDD
- Un fichier local ou distribué (HDFS) dont le format est configurable: texte, SequenceFile Hadoop, JSON…
- Une base de données: JDBC, HBase, Cassandra…
Un autre RDD auquel on aura appliqué une transformation (un filtre, un mapping…).
On peut simplement exporter le contenu d’un RDD dans un fichier, dans une base de données ou dans une collection.
Les capacités de cette technologie sont très importantes, on peut utiliser des clusters avec des milliers de nœuds et traiter des petabytes de données. Si votre jeu de données est trop grand pour être traité in memory, Spark va automatiquement utiliser uniquement les parties nécessaires pour pouvoir traiter ce jeu.
Principes de base
Apache Spark est entièrement codé en Scala, ce langage assez récent intègre les paradigmes de programmation orientée objet et de programmation fonctionnelle, avec un typage statique (voici le site officiel du langage).La notion centrale quand vous faites du Spark est le RDD, ou Resilient Distributed Dataset.
En décortiquant ce nom on peut un peu mieux le comprendre, on part de la fin :
Dataset : Il s’agit d’un jeu de données qui se parcourt comme une collection.
Distributed : Cette structure est distribuée afin d’être découpée pour être traitée dans les différents nœuds.
Resilient : Il est résilient, car il pourra être relu en cas de problème.
Le RDD est simple à créer et peut être obtenu à partir de multiples sources :
- Une collection (List, Set), transformée en RDD
- Un fichier local ou distribué (HDFS) dont le format est configurable: texte, SequenceFile Hadoop, JSON…
- Une base de données: JDBC, HBase, Cassandra…
Un autre RDD auquel on aura appliqué une transformation (un filtre, un mapping…).
On peut simplement exporter le contenu d’un RDD dans un fichier, dans une base de données ou dans une collection.
Les bibliothèques intégrées
Spark se base nativement sur le langage scala mais des API en Python ou en java existent. Je reviendrai plus tard sur ces langages.
L’écosystème Spark comporte ainsi aujourd’hui plusieurs outils :
- Spark pour les traitements “en batch”
- Spark Streaming pour le traitement en continu de flux de données
- MLlib pour le “machine learning”. Il s’agit d’une bibliothèque de méthodes d’apprentissage (type k-means…) optimisée pour Spark
- GraphX pour les calculs de graphes
- Spark SQL, une implémentation SQL-like d’interrogation de données.
- SparkR ou R on Spark, un package permettant de faire du spark depuis R, le langage de programmation spécialisé pour le traitement et l’analyse des données.
L’écosystème Spark comporte ainsi aujourd’hui plusieurs outils :
- Spark pour les traitements “en batch”
- Spark Streaming pour le traitement en continu de flux de données
- MLlib pour le “machine learning”. Il s’agit d’une bibliothèque de méthodes d’apprentissage (type k-means…) optimisée pour Spark
- GraphX pour les calculs de graphes
- Spark SQL, une implémentation SQL-like d’interrogation de données.
- SparkR ou R on Spark, un package permettant de faire du spark depuis R, le langage de programmation spécialisé pour le traitement et l’analyse des données.
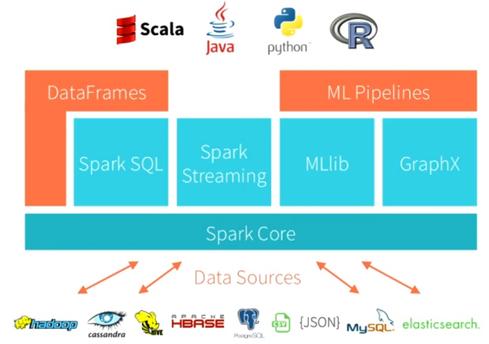
Les langages
Spark est écrit en Scala et peut être indifféremment utilisé en Java, en Scala et en Python.Scala : certaines fonctionnalités du langage comme les tuples, l’inférence de type, les case classes, les conversions implicites, rendent l’utilisation de Spark fluide. De plus, le Spark Shell, qui s’appuie sur le shell Scala, permet l’écriture et l’exécution de traitements en direct.
Python : on dispose, comme en Scala, d’un shell (PySpark), de tuples, d’un typage flexible… Mais certaines fonctionnalités purement Java ou Hadoop ne sont pas accessibles.
Java : La couche d’adaptation Java/Scala et le typage explicite nécessaire rend l’utilisation un peu plus lourde, mais reste acceptable.
R : Spark propose un package R permettant de piloter vos analyses depuis R en utilisant le langage R. Il s’agit d’un pont créé pour les data scientists qui ne ce sont pas encore mis à python et qui veulent utiliser apache spark.
https://www.stat4decision.com/fr/spark-boite-a-outils-du-big-data/
Préparation et lancement
https://www.stat4decision.com/fr/spark-boite-a-outils-du-big-data/
Topologie
Un cluster Spark se compose d’un master et d’un ou plusieurs workers. Le cluster doit être démarré et rester actif pour pouvoir exécuter des applications.
Le master a pour seul responsabilité la gestion du cluster et il n’exécute donc pas de code MapReduce. Les workers, en revanche, sont les exécuteurs. Ce sont eux qui apportent des ressources au cluster, à savoir de la mémoire et des cœurs de traitement.
Pour exécuter un traitement sur un cluster Spark, il faut soumettre une application dont le traitement sera piloté par un driver. Deux modes d’exécution sont possibles :
- mode client : le driver est créé sur la machine qui soumet l’application
- mode cluster : le driver est créé à l’intérieur du cluster.
Communication au sein du cluster
Les workers établissent une communication bidirectionnelle avec le master : le worker se connecte au master pour ouvrir un canal dans un sens, puis le master se connecte au worker pour ouvrir un canal dans le sens inverse. Il est donc nécessaire que les différents nœuds du cluster puissent se joindre correctement (résolution DNS…).
La communication entre les nœuds s’effectue avec le framework Akka. C’est utile à savoir pour identifier les lignes de logs traitant des échanges entre les nœuds.
Les nœuds du cluster (master comme workers) exposent par ailleurs une interface Web permettant de surveiller l’état du cluster ainsi que l’avancement des traitements. Chaque nœud ouvre donc deux ports :
un port pour la communication interne : port 7077 par défaut pour le master, port aléatoire pour les workers
un port pour l’interface Web : port 8080 par défaut pour le master, port 8081 par défaut pour les workers.
Lancement d’une application sur le cluster
Préparation et lancement
Pour être exécutée sur un cluster, une application Spark doit être packagée dans un JAR et disposer d’une classe avec une méthode "main".
Deux précautions doivent être prises :
- le contexte Spark doit être initialisé sans la déclaration setMaster(...)
- les chemins de fichiers doivent être accessibles par tous les workers : nous utilisons ici des chemins absolus.
(source: https://blog.ippon.fr/2014/11/20/utiliser-apache-spark-en-cluster/)
Comments
Post a Comment